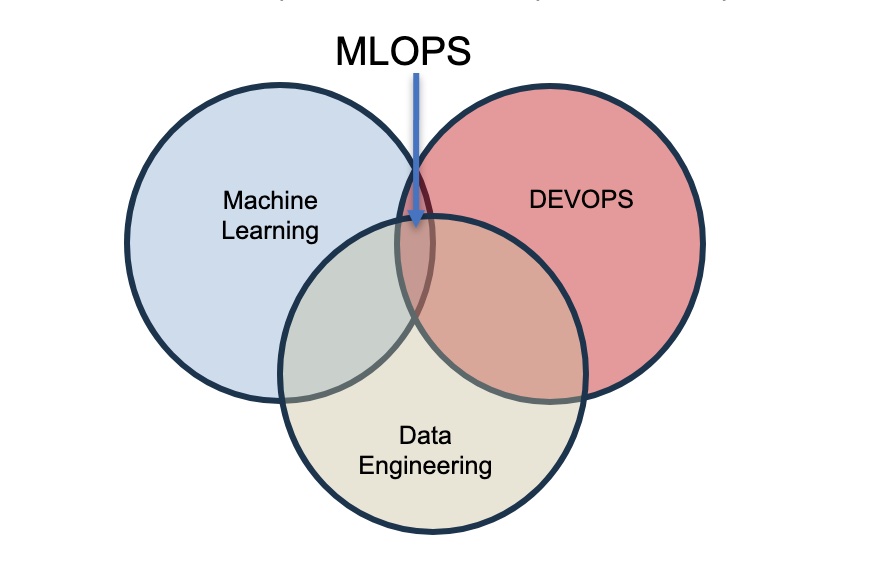
1/ Définition du MLOps
Le MLOps, également connu sous le nom de DevOps appliqué au Machine Learning, est une approche pluridisciplinaire conçue pour intégrer le développement de modèles de machine learning (ML) et leur mise en œuvre pratique.
Cette pratique s'inspire des principes du DevOps, comme l'intégration et la livraison continue, ainsi que l'automatisation des processus informatiques, et les adapte spécifiquement au domaine du machine learning.
MLOps est une culture et non seulement un outil. Au même titre que le DevOps, l’idée n’est pas que d’utiliser un tooling, mais d’adopter un ensemble de pratiques pour créer le modèle, et le livrer. Il ne s’agit pas de créer des modèles par Data Scientists, qui donnent leur code à un data engineer puis à un Devops SRE pour shipper le code. Cela nécessite d’adopter un ensemble de principes, qui permettront d’aller en production le plus rapidement possible sans créer de la dette technique.
Excellente vidéo conférence :https://www.youtube.com/watch?v=yYs_MYn4RQQ
2/ Principes MLOPS
Le cycle de vie du machine learning commence par la collecte et le traitement des données, suivi de l'entraînement et la validation des modèles sur ces données. Une fois le modèle optimal sélectionné, il est testé et déployé en production. Le processus se poursuit avec la surveillance continue et l'ajustement périodique du modèle pour garantir sa pertinence et son efficacité face à l'évolution des données et des besoins.
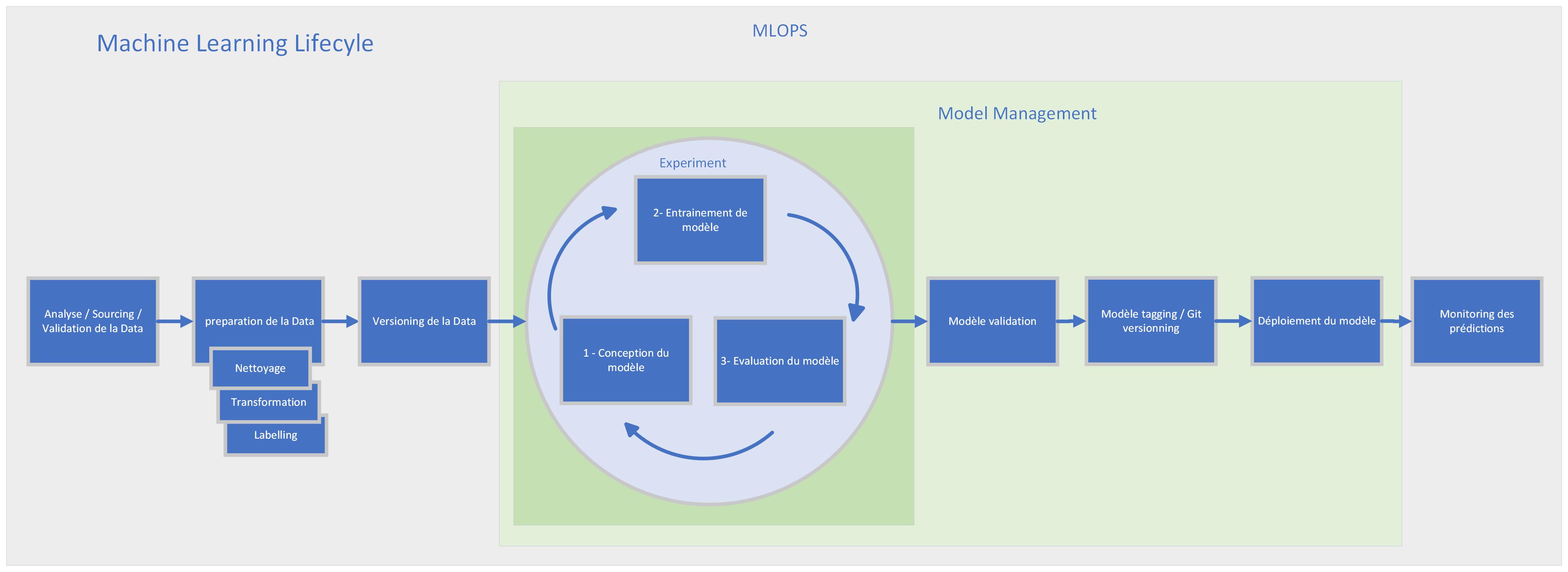
Culture MLOps:
De la même façon que la culture DevOps où les administrateurs et développeurs travaillent de concert, il est important de rassembler les dataScientist et les Data Engineers (ils ne doivent plus travailler en silo). L'équipe MLOps doit adopter une mentalité et un ensemble de pratiques spécifiques pour la création et la livraison de modèles. Il est essentiel d'embrasser certains principes qui favoriseront une mise en production rapide, tout en évitant l'accumulation de dette technique.
Automatisation :
En plus des étapes traditionnelles telles que la construction, le test et le déploiement, le MLOps encourage l'automatisation des tâches spécifiques à la gestion des systèmes ML, telles que le réentraînement des modèles. Il est également essentiel que, une fois formés, les modèles soient déployés de manière automatique.
Modèle pipeline
Vous utilisez une séquence avec des étapes data processing qui aboutit sur un modèle d’entraînement.
- Comment puis-je facilement stocker et versionner les “artefacts” ensemble ?
- Comment facilement paramétrer tout cet ensemble d’étapes ?
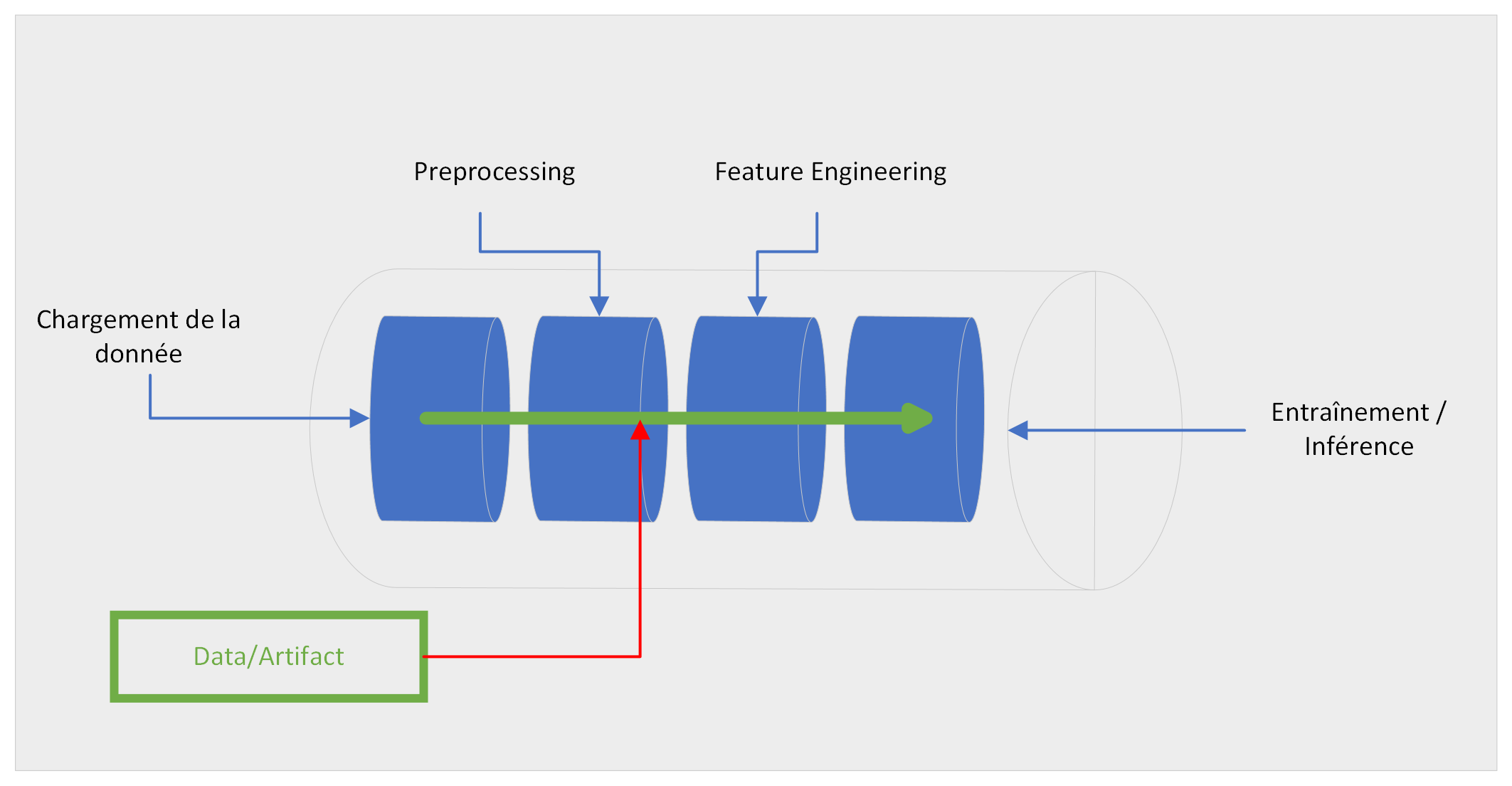
Il existe plusieurs frameworks pour gérer les modèles pipeline que vous pouvez utiliser. La plupart propose des applications au delà du modèle, voir même propose des fonctionnalités pour le domaine du Data Engeneering.
Voici quelques exemples d’outils (pour la plus part open source !) :
- Ploomber: https://ploomber.io/
- Prefect: https://www.prefect.io/
- Kedro: https://kedro.org/
- Dagster: https://dagster.io/
- DVC : https://iterative.ai
- AirFlow: https://airflow.apache.org/
Le registre de modèles
Un registre de modèles est un stockage central où une couche méta au-dessus d'un composant de stockage qui vous permet d'enregistrer et/ou de stocker votre modèle. Mais il y a plus à cela
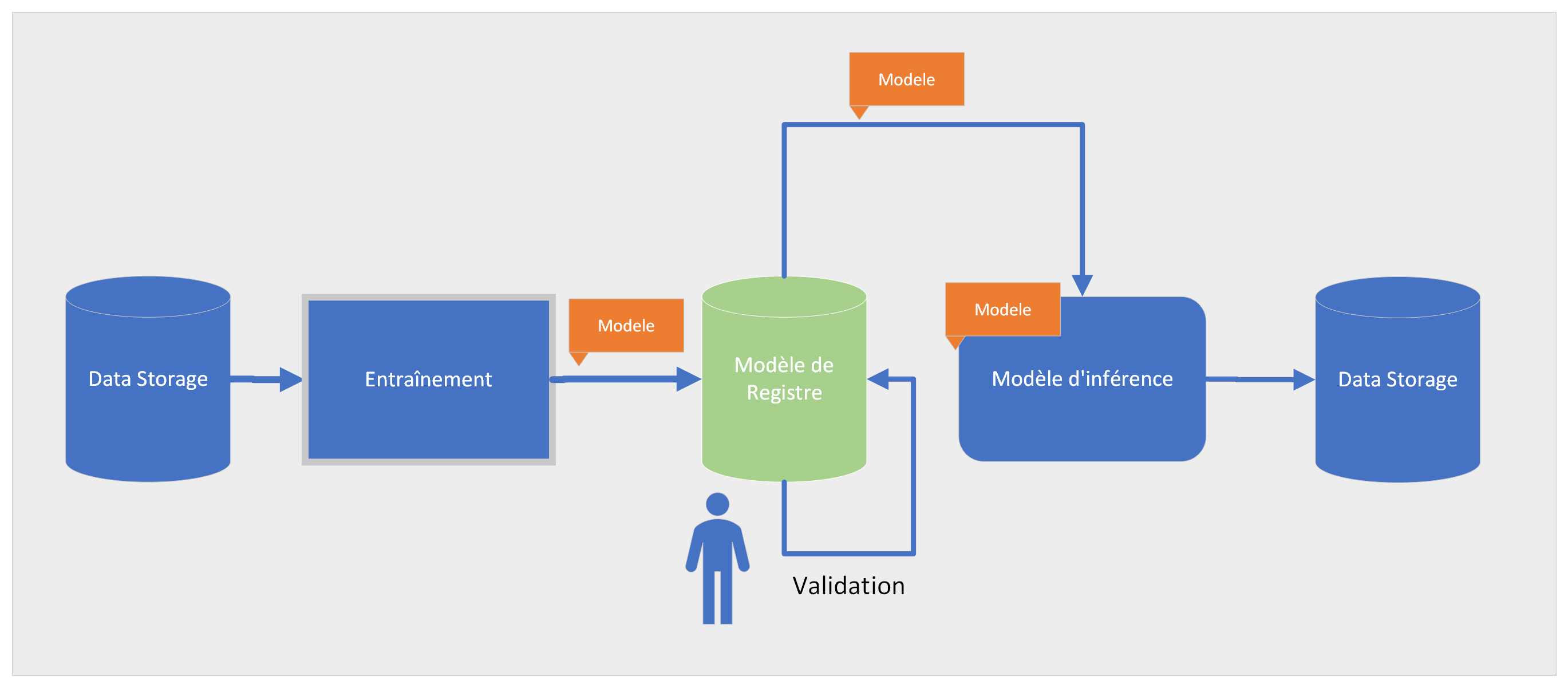
Typiquement, le registre de modèles vous aidera à :
- Garder une trace des différents modèles et leurs versions,
- Centraliser la collecte de meta-information de modèles (ex : quelles datas ont été utilisées pour entraîner le modèle),
- Facilement approuver/refuser et promouvoir une version de modèles,
- Lier vos expérimentations aux résultats du modèles
- Exposer et partager les artifacts des modèles de façon transparente…
Il existe aujourd’hui de nombreuses solutions open source & propriétaires spécialisées pour gérer les registres de modèles qui offrent de nombreuses fonctionnalités avancées.
Voici quelques exemples :
- neptune.ai: https://neptune.ai/home
- Comet : https://www.comet.com/site/
- MLflow: https://mlflow.org/
- Weights & Biases: https://wandb.ai/site
- + Toutes les solutions des grands Cloud providers (AWS Sagemaker, Vertex.ai, qui proposent des plateformes ML associées à leur infrastructures)
Les experiments
L’ensemble des projets ML suit un développement non linéaire : en effet ils nécessitent plusieurs étapes dans le processus de développement (algorithmes, qualification de la data, ajout de feutre, …) pour atteindre une performance suffisante. Garder une trace de ces expérimentations pour savoir ce qui a fonctionné ou non peut être complexe mais reste crucial pour réduire le temps de développement des équipes. Ces expérimentations tracées, permettent à de grandes équipes de travailler à plusieurs, de reprendre le travail des autres, de gagner du temps (vélocité) et garantissent la reproductibilité.
Mesurer le drift :
Un modèle peut voir ses performances se dégrader dans le temps. Ce phénomène est attribué à la « dérive conceptuelle (Drift) » : en effet les données sur lesquelles ils ont été entraînés ne reflètent plus les conditions actuelles ou les nouveaux schémas dans les données réelles. Cela nécessite une mise à jour ou un réentraînement périodique du modèle pour maintenir sa précision. Par conséquent, il est crucial de surveiller la performance des modèles de ML déployés et, si nécessaire, d'adopter une stratégie de réapprentissage automatique pour réajuster le modèle en cas de baisse de performance.
3/ Niveau de maturité des équipes MLOps
Le modèle de maturité MLOps vise à établir clairement les principes et les pratiques, tout en repérant les éventuelles insuffisances dans une mise en œuvre de MLOps.
Ce modèle sert également à montrer au client la manière d'accroître progressivement ses compétences en MLOps, sans avoir à tout entreprendre simultanément.
Il est recommandé que le client suive ce modèle comme une feuille de route pour :
- Évaluer l'ampleur des travaux nécessaires pour le projet ;
- Définir des critères de réussite ;
- Identifier les produits à livrer.
Ce modèle de maturité MLOps décrit cinq niveaux de compétence technique.
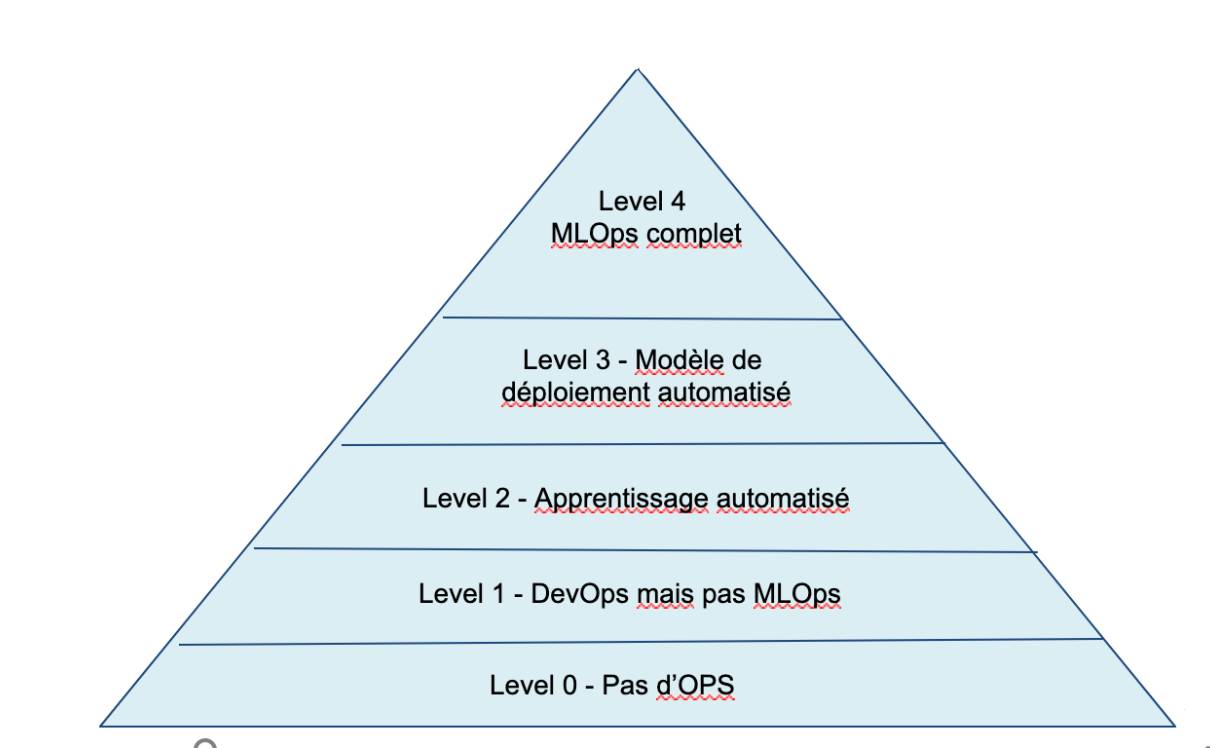
Source :
https://learn.microsoft.com/fr-fr/azure/architecture/ai-ml/guide/mlops-technical-paper
https://learn.microsoft.com/fr-fr/azure/architecture/ai-ml/guide/mlops-maturity-model
Level 0 : Pas d’Ops
| Level 3 : Modèle de déploiement automatisé
|
Level 1 : DevOps mais pas de MLOps
Level 2 : Apprentissage automatisé
| Level 4 : Opérations automatisées (MLOps complet)
|
Il existe d'autres modèles de maturité : Google et Redhat distinguent 3 cas:
- Level 0 : pas automatique (pas d'OPS - processus manuel )
- Level 1 : semi-automatique (pipelines) - automatisation du pipeline de ML
- Level 2 : automatique (CI/CD + pipelines) - automatisation du pipeline CI/
CD
En savoir plus :
- https://www.redhat.com/en/topics/ai/what-is-mlops#getting-started-with-mlops
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#mlops_level_1_ml_pipeline_automation
Conclusion
Mettre en place une architecture MLOps s'avère complexe. Cela nécessite de bien comprendre les enjeux d'automatisation des équipes DataScientist et Data Engineers. Pour le réussir, il faut que l'ensemble de l'équipe adopte ce mindset.
Cela passe en priorité par casser les silos entre les DataScientists et les Data Engineers, leur faciliter la tâche au quotidien et automatiser au maximum l'entraînement des modèles et de la data pipeline. C'est un chemin complet qu'il faudra suivre pas à pas, pour ne pas détériorer la vélocité de l'équipe. Trouver cet équilibre, c'est aussi comprendre où se situe la maturité de l'équipe.
La clé de succès repose sur la mise en place d'un registre de modèles et d'un modèle pieline, qui garantiront à l'équipe la reproduction des modèles, la traçabilité et la réduction des frictions lors des entrainements et le déploiement des modèles.
L'écosystème MLOps est devenu mature. Il existe de nombreuses solutions (pour la plupart open source) MLOPS telles que : DVC, ML Flow, KubeFlow, Neptune ou chez les Cloud Vendors (SageMaker, vertex, ...) Chacun de ces outils peuvent répondre aux problématiques de l'équipe, en fonction de son niveau de maturité.
Enfin il est crucial de fournir les ressources adéquates, notamment des Data Engineers et des Machine Learning Engineers. Les Machine Learning Engineers, en particulier, sont des professionnels expérimentés possédant une expertise en machine learning (comme la modélisation statistique et le deep learning) et des compétences en développement de logiciels, en ingénierie des données, ainsi qu'en déploiement de modèles de ML en production.
Si vous avez un projet MLOps, n'hésitez pas à nous contacter pour vous accompagner dans cette démarche. Notre équipe pourra vous aider dans toutes les étapes de ce processus.
Auteur : Roger Fernandez (société Emencia)
Ressources :
What is MLOPS ?
- https://learn.microsoft.com/fr-fr/azure/architecture/ai-ml/guide/mlops-technical-paper: ML technical paper de Microsoft qui est une référence dans le monde ML OPS
- https://pub.towardsai.net/mlops-demystified-6bee7a44ba9a : MLOps demystified
- https://towardsdatascience.com/what-is-mlops-everything-you-must-know-to-get-started-523f2d0b8bd8 : global overview ML OPS
- https://www.v7labs.com/blog/mlops-machine-learning-ops-guide : Machine Learning operations and how to implement it
- https://www.youtube.com/watch?v=XwTH8BDGzYk&list=PL3MmuxUbc_hIUISrluw_A7wDSmfOhErJK : Data Maturity Model video qui explique bien les niveau de maturité des équipes ML OPS
- https://learn.microsoft.com/fr-fr/azure/architecture/ai-ml/guide/mlops-maturity-model : Model de Maturité MLOPS - article en francais sur les 5 différents niveaux.
REX (Retour d’Experience) :
- https://www.youtube.com/watch?v=CB1YIsxQRtc : REX ML Ops par Simon Stiebellehner (MLOps Engineer)
- https://www.youtube.com/watch?v=yYs_MYn4RQQ : Rex Art of Building MLOps Platforms for Seamless Data
Tutorial
https://github.com/DataTalksClub/mlops-zoomcamp : Excellents tutoriaux sur le MLOPS avec des exemples sur MLFLOW